

5 Ways ML is Killing the 90% False Positive Problem in AML
Traditional rule-based transaction monitoring is broken by design. Machine learning is rebuilding it from the ground up , contextually, adaptively, and at a scale no compliance team could ever manually manage.
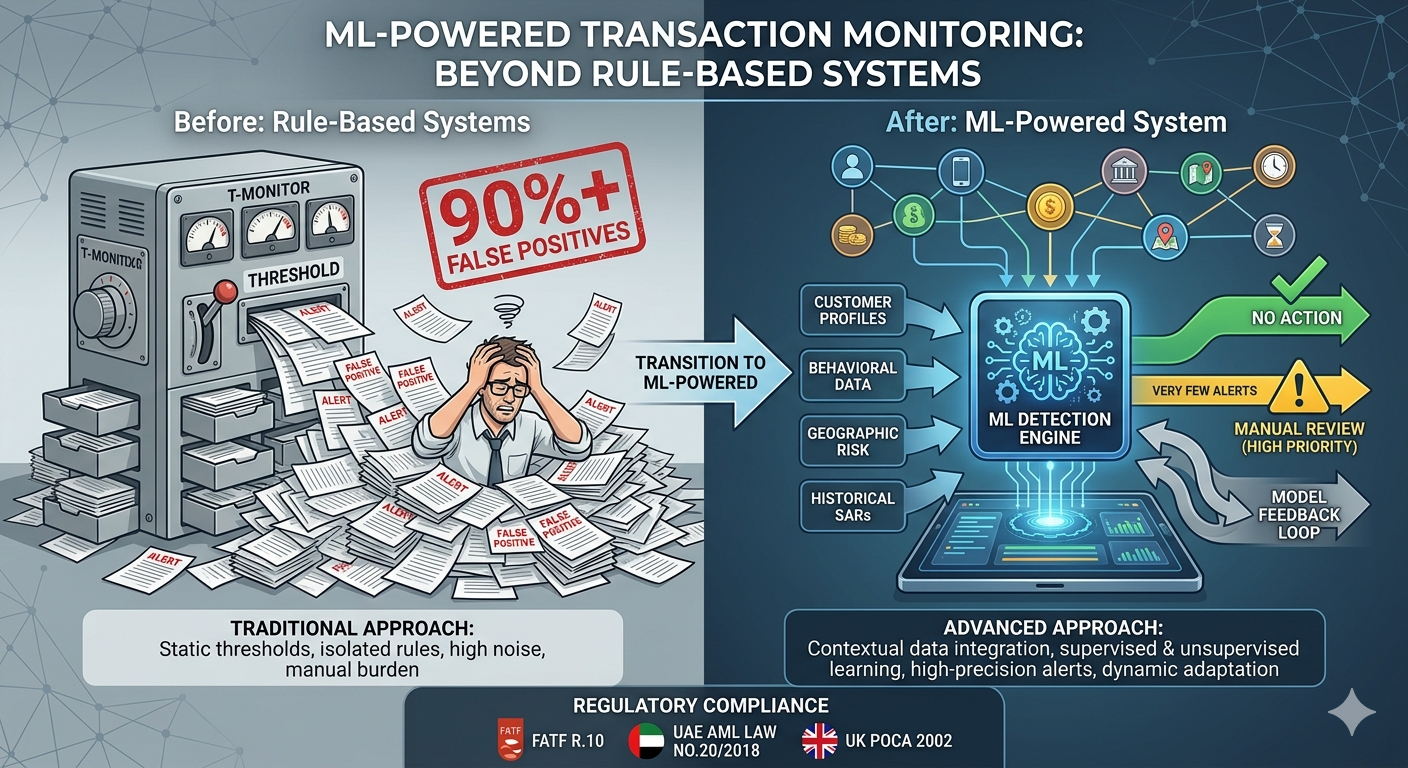
Picture a compliance analyst arriving at work on a Monday morning to find 800 alerts waiting in the queue. Of those, if historical norms hold, fewer than 80 will involve any genuinely suspicious activity. The other 720 are noise , false positives generated by rules that don’t know the difference between a CFO wiring funds to a subsidiary and a money launderer layering proceeds through shell companies.
This is the daily reality inside most major financial institutions today. And it’s not a minor inefficiency: it’s a structural failure that costs the industry billions in wasted investigator hours, drives critical analyst burnout, and , perversely , makes institutions worse at detecting actual financial crime because the signal drowns in the noise.
False Positive Rate (FPR): The proportion of legitimate transactions that a monitoring system incorrectly flags as suspicious. In AML, a 90%+ FPR means that for every genuine alert that reaches an investigator, nine alerts consume investigator time before being dismissed as non-suspicious. This inefficiency is compounded when each dismissal takes over 60 minutes of analyst effort.
Machine learning doesn’t just incrementally improve these numbers , it reframes what transaction monitoring can be. Instead of static thresholds that ask “did this transaction exceed $X?”, ML models ask “is this transaction consistent with what we know about this customer, their network, their industry, and their historical behaviour patterns?” The two questions are philosophically worlds apart.
Here are the five most impactful ways ML is dismantling the false positive problem , and rebuilding transaction monitoring as a dynamic, intelligent, self-learning detection engine.
The fundamental problem with rule-based systems isn’t that the rules are wrong , it’s that they’re blind to context. A rule that flags all cash deposits over $9,000 will correctly catch some structuring attempts. It will also flag every small business owner who deposits slightly less than their weekly cash takings, every person who received a large gift, and every legitimate customer whose transaction pattern simply happens to cross an arbitrary line.
ML-powered contextual monitoring works differently. Rather than asking whether a transaction crosses a fixed threshold, it asks whether this transaction is anomalous for this specific customer, given everything the system knows about them: their occupation, transaction history, peer group behaviours, KYC data, counterparty network, industry norms, and geographic patterns.
Quantexa’s contextual monitoring research found that rule-based systems typically use fewer than 30 data points to generate a Level 1 alert , yet investigators need more than 100 data points to complete a meaningful investigation. ML-powered contextual monitoring bridges this gap at the point of alert generation, dramatically reducing the analyst workload per alert.
HSBC’s Global Trade and Receivable Finance team processes over US$500 billion in documentary trade per year. At that scale, rule-based approaches would produce an unmanageable volume of alerts , many triggered simply because trade transactions looked unusual in isolation when, in context, they were entirely legitimate related-party transfers. By deploying contextual ML that integrates internal transaction data, KYC records, Legal Entity Identifier (LEI) data from GLEIF, and external reference sources like Bloomberg and Bureau van Dijk, HSBC’s system can identify that a foreign payer and receiver are in fact the same legal entity initiating a structured transaction , suppressing the false alarm entirely.
Contextual ML Eliminates Related-Party False Alarms
HSBC deployed an AI-based AML system that connects internal transaction data with KYC records, LEI data, and external reference sources to build a full contextual picture of each trade. The system identifies cases where transactions that appear suspicious in isolation are entirely legitimate when viewed in the context of the counterparties’ corporate relationships. This contextual layer enabled a significant reduction in false positives while maintaining detection coverage for genuine risks.
How Contextual Monitoring Is Built
Data Integration Layer
Internal transaction history, KYC/CDD data, and customer risk scores are consolidated with external data sources (LEI registries, corporate ownership databases, adverse media feeds) into a unified data model.
Entity Resolution
ML algorithms resolve entities across data sources , matching variations of company names, jurisdictional structures, and beneficial ownership chains , to build an accurate picture of who the customer really is.
Contextual Scoring
Each transaction is scored not just on its own characteristics but on its contextual plausibility , how consistent it is with the customer’s established behaviour, peer-group norms, and disclosed business purpose.
Alert Prioritisation
Alerts are ranked by a composite risk score, surfacing the highest-priority cases first and suppressing alerts that the model identifies as contextually explainable, measurably reducing the false positive volume reaching investigators.
When a Suspicious Activity Report (SAR) is filed, it represents something rare and valuable: a confirmed signal of genuine suspicious activity in a sea of transactions. Supervised machine learning treats these historical SARs as a training dataset, learning the multivariate feature patterns that distinguish confirmed suspicious behaviour from the vast majority of legitimate financial activity.
Rather than relying on a compliance officer’s intuition to write a rule , “flag transactions to country X that exceed $Y” , supervised models learn directly from the data what patterns actually precede confirmed suspicious transactions. The models can identify combinations of dozens of features simultaneously: transaction timing, counterparty geography, account age, velocity patterns, product type, and hundreds of other variables, weighted by their historical predictive power.
Gradient Boosted Trees
Highly effective for structured tabular transaction data. Handles non-linear relationships and feature interactions that rule-based systems miss entirely.
Random Forests
Ensemble of decision trees that reduces overfitting and provides robust performance across diverse transaction types and customer segments.
LSTMs / Recurrent NNs
Captures temporal dependencies in transaction sequences , detecting patterns that unfold over time rather than existing in a single transaction.
Support Vector Machines
Effective in high-dimensional feature spaces, particularly for identifying clear boundary conditions between suspicious and legitimate behaviours.
Supervised learning has a critical constraint: it can only detect crime patterns that resemble those already in its training data. Novel money laundering typologies , particularly emerging methods that haven’t yet generated confirmed SARs , are invisible to purely supervised models. This is why leading institutions deploy supervised and unsupervised methods in combination, not isolation.
Supervised ML Accelerates Detection and Investigation
JPMorgan Chase’s integration of AI into its AML processes in 2023 resulted in a measurable improvement across the detection pipeline. By training classification models on historical confirmed cases, the institution achieved substantially higher detection of genuinely illicit activities, while simultaneously reducing the time investigators spent per case. The system’s ability to pre-populate investigation context , identifying relevant counterparties, surfacing corroborating transactions, and flagging network connections , reduced analyst time per alert materially.
Here is the uncomfortable truth about any detection system that learns from historical cases: it can only detect what it already knows to look for. Money launderers don’t read compliance playbooks , they actively innovate to exploit gaps in detection logic. New typologies, novel cryptocurrency layering structures, and emerging trade-based money laundering schemes may never have generated a SAR before their first occurrence in your institution.
Unsupervised learning addresses this limitation by learning what normal financial behaviour looks like , and flagging deviations from normality, regardless of whether those deviations match any previously known crime pattern. No labelled training data required. No prior SAR needed. Just a statistical model of what legitimate activity looks like, and an alert when behaviour departs significantly from that baseline.
Core Unsupervised Techniques in AML
Autoencoders
Neural networks trained to reconstruct normal transaction patterns. Transactions that cannot be accurately reconstructed , because they deviate from learned norms , are flagged as anomalous.
Isolation Forests
Isolates anomalies by constructing random decision trees. Data points that are isolated quickly (in fewer splits) are statistically unusual , and potentially suspicious.
DBSCAN Clustering
Density-based clustering identifies transaction patterns that form statistically unusual groupings , useful for detecting structuring, burst activity, and peer-group outliers.
One-Class SVMs
Trained on legitimate transactions only, these models define the boundary of normal behaviour and classify any activity falling outside that boundary as anomalous.
By learning a statistical model of normal financial behaviour from transaction history, unsupervised systems can flag deviations that warrant investigation without requiring prior knowledge of the specific crime typology involved. This is particularly valuable for detecting novel money laundering typologies and market manipulation patterns for which historical labelled examples do not exist.
, International Journal of Advanced Signal & Image Sciences, 2025
The most effective AML ML deployments combine supervised and unsupervised approaches in a hybrid architecture: supervised models handle known typologies efficiently with high precision; unsupervised models cast a wider net for novel behaviour; and a human review layer applies domain expertise to edge cases where algorithmic confidence is lower. This combination captures both depth (known patterns) and breadth (unknown anomalies) simultaneously.
Money laundering is rarely a solitary act. It involves networks of accounts, entities, jurisdictions, and intermediaries , often deliberately structured to obscure the connection between the source of funds and their ultimate destination. Traditional transaction monitoring examines each transaction in isolation, making it fundamentally blind to the network patterns that are the hallmark of sophisticated laundering operations.
Graph analytics applies network science to the relationship structures that financial transactions create. Every transaction creates an edge in a graph between a sending and receiving node. As transactions accumulate, patterns emerge: circular payment chains, layered shell company networks, high-degree intermediary nodes, and unusual community structures , all of which are invisible to transaction-by-transaction analysis but immediately apparent in a graph representation.
Graph Neural Networks (GNNs) learn representations of nodes (accounts, entities) and edges (transactions) in the financial network. Models like FastGCN, developed in research by MIT and IBM, have demonstrated the ability to identify suspicious network structures , including circular flows and shell company chains , at scales and speeds that no manual investigation could match. The same MIT/IBM collaboration also released AMLSim, a synthetic dataset generator to advance graph-based AML research.
What Graph Analytics Can Detect That Rules Cannot
- Circular layering structures: Funds moving through a series of accounts in a closed loop before being extracted as “clean” , a classic layering technique invisible to per-account monitoring.
- Shell company networks: Mapping beneficial ownership through chains of legal entities across multiple jurisdictions to identify the true source and destination of funds.
- High-degree intermediaries: Accounts acting as hubs for funds from many disparate sources , a structural red flag for money mule activity even when individual transactions appear unremarkable.
- Collusive behaviour: Multiple accounts exhibiting coordinated transaction timing or patterns, suggesting a common controlling intelligence even when no formal connection is disclosed.
- Cross-border fund tracing: Following funds across jurisdictional boundaries in real time, enabling FIUs to identify the ultimate beneficiary of complex layered transactions.
Entity Resolution and Network Analytics at Global Scale
Quantexa’s contextual monitoring platform uses graph analytics to resolve entities across disparate internal and external data sources and build relationship networks around each customer. By mapping the full corporate ownership structure around each counterparty , connecting legal entities through beneficial ownership data, LEI registries, and transaction history , the system identifies cases where transactions that appeared suspicious in isolation were legitimate related-party transfers, suppressing false alerts while surfacing genuine network-level risks that rule-based systems completely missed.
Rule-based systems are static. Once written, a rule does exactly what it was programmed to do , and nothing more. When money launderers adapt their methods, the rules don’t adapt with them. Updating rules requires compliance officers to detect the new pattern, write a new rule, test it, and deploy it. By the time this process completes, the laundering method may already have evolved again.
ML models with continuous learning capabilities are fundamentally different: they improve with every new transaction processed and every case resolved. When an investigator closes an alert as a true positive or dismisses it as a false positive, that feedback is fed back into the model as new training data. The model becomes more precise with each iteration, calibrated to the institution’s specific customer base, transaction patterns, and regulatory environment.
Financial crime environments are dynamic. Perpetrators continuously adapt their tactics to circumvent detection systems , a process sometimes called “adversarial adaptation.” Continuous learning ML systems that incorporate analyst feedback create an adaptive arms race that static rule sets cannot participate in. Each analyst decision becomes a training signal that makes the model more accurate for future cases.
Components of a Continuous Learning AML System
Human-in-the-Loop Feedback
Every analyst decision , confirm suspicious, dismiss as legitimate, or escalate , is captured as structured feedback that is systematically fed back into model training pipelines.
Drift Detection
Statistical monitoring of model performance detects when transaction pattern distributions shift , indicating either a genuine change in customer behaviour or the emergence of a new typology requiring model recalibration.
Periodic Retraining
Models are retrained on updated datasets that include recent confirmed cases, ensuring that the institution’s detection capability keeps pace with the current threat environment rather than reflecting conditions from months or years past.
Regulatory Alignment Updates
When regulators or FATF issue updated typology guidance, models can be fine-tuned to increase sensitivity to the newly identified patterns , ensuring compliance with evolving regulatory expectations.
Continuous Learning at Planetary Scale
Visa’s AI-driven analytics platform, which processes billions of transactions across its global network, demonstrates the potential of continuous learning in financial crime prevention. By continuously updating its fraud detection models against the latest transaction data, Visa prevented $40 billion worth of fraudulent transactions in 2023 alone , a result achievable only through the combination of scale, real-time processing, and adaptive learning that static rule-based systems simply cannot match.
Rule-Based Systems vs. ML-Powered Monitoring: A Direct Comparison
The contrast between traditional and ML-driven approaches isn’t just incremental , it’s architectural. Understanding the structural differences helps explain why institutions that have successfully deployed ML are reluctant to revert to rule-based approaches, even where legacy systems still exist alongside newer technology.
| Dimension | Rule-Based Systems | ML-Powered Systems |
|---|---|---|
| False Positive Rate | >90% typical | Significantly reduced; varies by model |
| Data Points per Alert | <30 typically | 100+ features analysed simultaneously |
| Adaptation to New Typologies | Manual update required; slow | Continuous learning; near-real-time adaptation |
| Contextual Awareness | None , threshold-based | Full customer and network context |
| Network/Graph Analysis | Not possible | Core capability (GNNs, graph analytics) |
| Novel Typology Detection | Blind to unknown patterns | Unsupervised anomaly detection |
| Explainability | High , rules are transparent | Variable , XAI tools required for black-box models |
| Regulatory Acceptance | Well-established; widely accepted | Growing acceptance; model validation required |
| Implementation Complexity | Lower initial complexity | Higher; requires data science expertise and governance |
| Investigator Productivity | Low , high false positive burden | High , pre-qualified, contextualised alerts |
Regulatory Framework: Aligning ML Monitoring with Compliance Obligations
Customer Due Diligence & Ongoing Monitoring: FATF Recommendation 10 requires financial institutions to conduct ongoing monitoring of business relationships. FATF’s 2021 guidance on new technologies explicitly endorsed AI and ML for AML compliance, while emphasising requirements for human oversight, model validation, and auditability. ML systems must therefore be designed with explainability and governance frameworks that satisfy these requirements.
UAE Federal Decree-Law No. 20/2018: The UAE’s AML law establishes risk-based monitoring obligations and requires institutions to deploy transaction monitoring systems commensurate with their risk profile. The CBUAE has increasingly encouraged the adoption of advanced analytics in compliance programs, and ML-powered systems , when properly validated and governed , satisfy and often exceed the monitoring obligations set out in the decree.
Proceeds of Crime Act 2002: Under UK POCA, financial institutions have a legal obligation to submit Suspicious Activity Reports (SARs) when they know or suspect money laundering. ML systems that generate more accurate, better-contextualised alerts , reducing both false positives and false negatives , directly support an institution’s ability to meet this obligation. The FCA has acknowledged that risk-based approaches using advanced analytics can satisfy POCA monitoring requirements.
Key Takeaways
- Rule-based systems generate over 90% false positives because they evaluate transactions in isolation, without context , ML fixes this at the architectural level by incorporating hundreds of contextual features per alert.
- Supervised ML trained on historical SARs dramatically improves alert precision for known typologies; unsupervised anomaly detection catches novel laundering methods that no rule or SAR could anticipate.
- Graph Neural Networks are uniquely capable of exposing network-level laundering structures , circular flows, shell company chains, and money mule hubs , that are structurally invisible to transaction-by-transaction monitoring.
- Continuous learning models adapt to new typologies as they emerge, creating an adaptive detection capability that keeps pace with evolving criminal methodologies rather than always fighting the last war.
- FATF, UAE, and UK regulatory frameworks support ML adoption when accompanied by appropriate model validation, explainability tools, and human oversight , compliance is a design requirement, not an afterthought.
- The most effective deployments combine supervised, unsupervised, and graph-based methods in hybrid architectures , no single ML approach is sufficient on its own.
Frequently Asked Questions
Can ML completely replace rule-based transaction monitoring?
In practice, most institutions deploy ML alongside , rather than as a complete replacement for , certain rule-based logic. Some rules have regulatory, policy, or legal bases that require they remain explicit and auditable regardless of ML performance. However, ML can substantially reduce reliance on threshold-based rules for general risk detection, shifting the primary detection engine to adaptive models while retaining specific rule-based controls for defined regulatory scenarios. The long-term trajectory in the industry is clearly towards ML-dominant architectures with rules serving as a complementary layer for specific regulatory obligations.
How do regulators view ML-powered transaction monitoring?
Regulatory acceptance of ML in AML has grown substantially. FATF’s 2021 guidance explicitly endorsed AI and ML for AML/CFT compliance. The FCA, FinCEN (through its Innovation Hours Program), and CBUAE have all signalled openness to advanced analytics in compliance programs. The key requirements are model validation (demonstrating the model performs as intended), explainability (being able to articulate why an alert was generated), auditability (maintaining records of model decisions), and human oversight (ensuring a human reviews model outputs before regulatory actions are taken). Institutions that build these governance requirements into their ML systems from the outset generally find the regulatory pathway manageable.
What data is needed to train an effective AML machine learning model?
For supervised models, historical labelled data , transactions linked to SAR outcomes or investigation results , is the foundation. The quality and completeness of this labelled dataset substantially determines model performance. Most institutions face the challenge that labelled datasets are imbalanced (confirmed suspicious transactions represent less than 1% of total volume), which requires techniques like SMOTE oversampling, cost-sensitive learning, or ensemble methods to address. For unsupervised models, large volumes of unlabelled transaction history are sufficient. Graph-based models additionally require network relationship data: counterparty identifiers, entity ownership data, and ideally external beneficial ownership registries. Data governance, privacy compliance with GDPR or equivalent frameworks, and data quality management are all critical prerequisites.
How is explainability addressed in AML machine learning models?
Explainability is one of the most important practical requirements for AML ML deployment, since investigators need to understand why a transaction was flagged in order to conduct a meaningful investigation , and regulators expect that SAR filing decisions can be justified. Techniques commonly used include SHAP (SHapley Additive exPlanations) values, which quantify the contribution of each feature to an individual model decision; LIME (Local Interpretable Model-Agnostic Explanations); and inherently interpretable models like gradient boosted trees, which provide feature importance scores. Many AML platforms now include automated natural-language explanation generation that converts model feature weights into investigator-readable narratives, significantly reducing the explainability burden on compliance teams.
What is the difference between AML transaction monitoring and fraud detection ML?
While both use similar ML techniques, AML transaction monitoring and fraud detection have distinct objectives. Fraud detection is primarily concerned with protecting the institution and its customers from immediate financial loss , it prioritises real-time decision-making (often in milliseconds) at the point of transaction authorisation. AML transaction monitoring is primarily concerned with regulatory compliance , detecting patterns that may indicate money laundering, which often unfolds over days, weeks, or months across multiple transactions. AML therefore typically operates in near-real-time or batch mode, incorporates a much wider historical window, places greater emphasis on network analytics and entity relationships, and is more directly linked to SAR filing obligations. Both domains increasingly use graph analytics, NLP, and deep learning, and some institutions deploy unified financial crime platforms that address both objectives.
How do ML models handle the imbalanced dataset problem in AML?
Imbalanced datasets , where suspicious transactions represent a tiny fraction of total volume (often well below 1%) , are a fundamental challenge for supervised AML models. If left unaddressed, models tend to predict “legitimate” for every transaction and still achieve 99%+ accuracy, which is operationally useless. Solutions include: oversampling minority classes using SMOTE (Synthetic Minority Over-sampling Technique) or ADASYN; undersampling the majority class; using cost-sensitive learning that assigns higher misclassification costs to false negatives (missed suspicious transactions); ensemble approaches that combine multiple models with complementary biases; and threshold calibration to adjust the decision boundary towards higher recall at the cost of precision. The right combination depends on the institution’s specific risk tolerance and regulatory environment.
The Verdict: ML Isn’t Optional , It’s Structural
The 90% false positive problem isn’t a quirk of a particular institution’s rule configuration , it’s an inevitable consequence of applying static, threshold-based logic to a complex, context-dependent, ever-evolving detection problem. Rule-based systems were the best available technology when they were built. They are no longer.
Machine learning doesn’t just improve the numbers at the margins. It redefines what transaction monitoring can be: a dynamic, context-aware, network-intelligent, self-improving detection engine that gets better with every transaction processed and every investigation completed. For compliance teams drowning in false positive queues, for FIUs struggling to find genuine suspicious activity in mountains of noise, and for institutions facing regulatory scrutiny over the quality of their AML programs, this is not an incremental upgrade , it’s a fundamental transformation.
The institutions leading the field , HSBC, JPMorgan, Visa , aren’t using ML because it’s novel. They’re using it because, at scale, nothing else works. And as the regulatory community increasingly recognises and endorses ML-based compliance programs, the question is shifting from whether to deploy ML in transaction monitoring to how quickly institutions can do so with adequate governance, explainability, and validation in place.
The false positive problem isn’t killing compliance , but it is consuming the resources that genuine financial crime detection needs. ML is the structural fix it has been waiting for.





